Improving SEO with Dynamic Rendering for WebAssembly Sites
Dynamic Rendering SEO Optimization for Blazor WebAssembly
This website is built using Blazor WebAssembly, a framework that allows for running C# code directly in the browser via WebAssembly. Unlike traditional server-side rendering, where the server is responsible for delivering the entire page content, Blazor WebAssembly delegates much of the work to the client. This means that when a user visits the site, the browser is responsible for making requests to APIs, running JavaScript, and rendering the content on the page.
While this approach offers many benefits, such as improved interactivity and a smoother user experience, it also presents challenges. Since much of the content is rendered on the client side, search engine bots may have difficulty properly indexing the website. This can result in incomplete indexing, where search engines are unable to crawl or fully understand the content, potentially impacting SEO performance.
For example, when Google fails to index or correctly parse the content of your website it could look like the following for blazor:
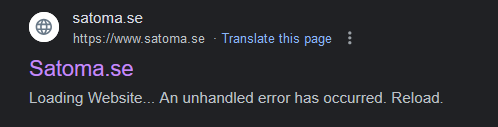
The Challenge and My Solution
After exploring several options, I found that many solutions were either too expensive or overly complicated for my needs. Paid services like Prerender.io offer dynamic rendering as a service, but they require redirecting requests to an external server to generate the static content, adding complexity and potentially increasing costs. Additionally, many solutions required significant changes to my infrastructure, which didn't fit well with the simplicity of a traditional web host setup where you just want to upload your files and have everything run smoothly.
Other solutions, such as running the website as a Blazor Server, where content is rendered on the server and sent to the client, didn't work for my use case. While Blazor Server can solve the issue of rendering content server-side, they usually do not work with traditional web hosts, it would mean relying on an external platform to host the server-side rendering. For example, platforms like Azure Web Apps (e.g., azurewebsites.net) are often used for Blazor Server applications, which require a more complex setup and ongoing dependency on a third-party service. I wanted to avoid this dependency. Instead, I preferred to keep things simple, with a traditional web host where I could upload everything to my own domain without needing to rely on external services or complex server-side infrastructure.
To solve this, I created a custom solution using Puppeteer and Node.js. Puppeteer is a headless browser automation tool that allows you to programmatically control a browser, simulate user interactions, and capture fully rendered pages. I wrote a script that can run on a local version of my Blazor WebAssembly website, hosted through a Visual Studio project at the normal localhost:7273.
The script essentially loads the website as if it were a real user, waits for the content to load and render, and then captures a static version of the fully rendered HTML. This static version can be saved and served specifically to search engine bots or used for SEO purposes, ensuring that they receive the same content that a user would see when interacting with the live site. This approach was simple, cost-effective, and didn't require altering my existing hosting infrastructure.
It's important to note that this technique is not the same as malicious cloaking. Instead, it's recognized by Google as dynamic rendering in the offical Google docs, a method that allows search engines to view the same content as users, ensuring accurate indexing without the deceptive practices associated with cloaking; However, it is worth nothing that this does indeed use the same techniques as cloaking, but the main differentiating factor is if it is malicous or not.
The Core Script and How It Works
The script uses Puppeteer for headless browsing and JSDOM for HTML manipulation to ensure search engine bots index the fully rendered content of a Blazor WebAssembly website. Here's how it works:
Duplication avoidance using Canonical Links: The script relies on canonical URLs to avoid duplicate pages, ensuring that each page is rendered from its authoritative version. If a page is accessible via multiple URLs, only the canonical URL (from the tag) is processed. This avoids duplicates and ensures proper indexing.
Resolving link locally and live: The canonicalBaseUrl parameter you provide (e.g., https://www.satoma.se) determines how internal links are handled. Even if the website is hosted on a local server (e.g., localhost), the script will only follow links that match the canonical base URL, ensuring no external URLs are crawled.
The script always transforms fully qualified URLs (e.g., https://localhost:7273/page1) into relative URLs. This allows the script to crawl and generate the correct structure for local testing or generation, while still working seamlessly for the live website when hosted on the canonical domain.
With both of these attributes it means:
The script only follows internal links, ensuring each link matches the specified canonicalBaseUrl.
When the site is hosted locally, the script automatically converts fully qualified URLs into relative ones, making it suitable for local testing and content generation. For example, if the site is hosted on "localhost" but a link points to the full URL (e.g., https://www.satoma.se/page1), the script will resolve it to a relative URL (/page1), as long as the canonicalBaseUrl correctly points to www.satoma.se.
External links or incorrectly formatted URLs are ignored, ensuring the crawl remains focused on the website's content.
Rendering and Saving Pages: The script loads each page, waits for it to fully render, then strips out unnecessary <script></script> tags (since search engine bots dont need them). It saves the fully rendered HTML to disk, to be served later specifically to bots, ensuring that bots index the content exactly as users would experience it, with no dynamic elements that could hinder SEO.
Automatic Sitemap: The script will also automatically generate a sitemap.xml for you just because it already has crawled the entire website it is just in the case that you want to use it. It is not particularly smart and sets the priority based on how many slashes(/) there is in the relative path and sets the timestamp to the current time.
After the script has finished running it will have generated a file structure for you which you can serve to bots, that looks something like the following:
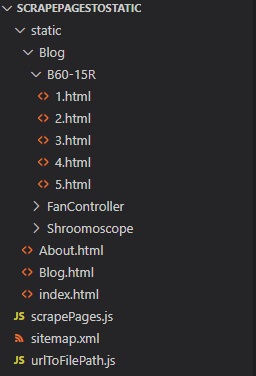
NOW THE FOLLOWING SCRIPT SHOULD ALLOW YOU TO GENERATE A STATIC VERSION OF YOUR WEBSITE; HOWEVER, THE ISSUE OF REDIRECTING ONLY BOTS TO THIS STATIC VERSION IS REMAINING, GO TO THE NEXT PAGE TO SEE HOW TO DO THAT!
The script implementation
The main script(scrapePages.js):
Supporting functions for main script(urlToFilePath.js):
[1]
Dynamic Rendering SEO Optimization for Blazor WebAssembly
2024-12-01 |
[2]
Bot detection and server side routing
2024-12-01 |